What is GenHMR?
GenHMR (Generative Human Mesh Recovery) is an AI tool that analyzes videos to detect and generate 3D poses and models of people. It works in two main stages: first creating multiple possible 3D poses and selecting the most likely one, then refining that pose to better match the original video.
This innovative technology has the potential to replace traditional motion capture methods by eliminating the need for marker suits. While highly accurate in many scenarios, it does have some limitations with complex movements and wide-angle shots.
Overview of GenHMR
| Detail | Description |
|---|---|
| Name | GenHMR |
| Purpose | Detects and generates 3D human poses and models from video footage. |
| GitHub Page | GenHMR GitHub Page |
| Official Paper | GenHMR Paper on arXiv |
GenHMR AI Guide
Step 1: Load Video
Action: Click on the "Load Video" option.
What Happens: Upload the video file you want to edit. This is the video where you’ll separate the object from its background.
Step 2: Clear Clicks
Action: If you need to remove any previous selections or annotations, click on the "Clear Clicks" option.
What Happens: This will reset any previous inputs, allowing you to start fresh or correct any mistakes.
Step 3: Foreground Output
Action: After processing the video, click on the "Foreground Output" option.
What Happens: GenHMR AI will generate the foreground output, which is the object separated from the background. You can preview this output and save it for further use.
Key Features of GenHMR
Two-Stage Processing
Uses a two-stage approach: first generating multiple possible 3D poses, then refining them to match the video footage accurately.
Uncertainty-Guided Sampling
Intelligently generates and selects the most likely 3D poses based on confidence levels in the first stage.
2D Pose-Guided Refinement
Fine-tunes the initial 3D poses to better match the original 2D video footage, improving accuracy.
Markerless Motion Capture
Eliminates the need for traditional motion capture suits with markers, generating 3D models directly from video.
Real-Time Processing
Processes video footage efficiently to generate 3D models in real-time, making it suitable for live applications.
Multi-Person Detection
Capable of detecting and generating 3D poses for multiple people in complex scenes like crowded environments.
Advanced Training System
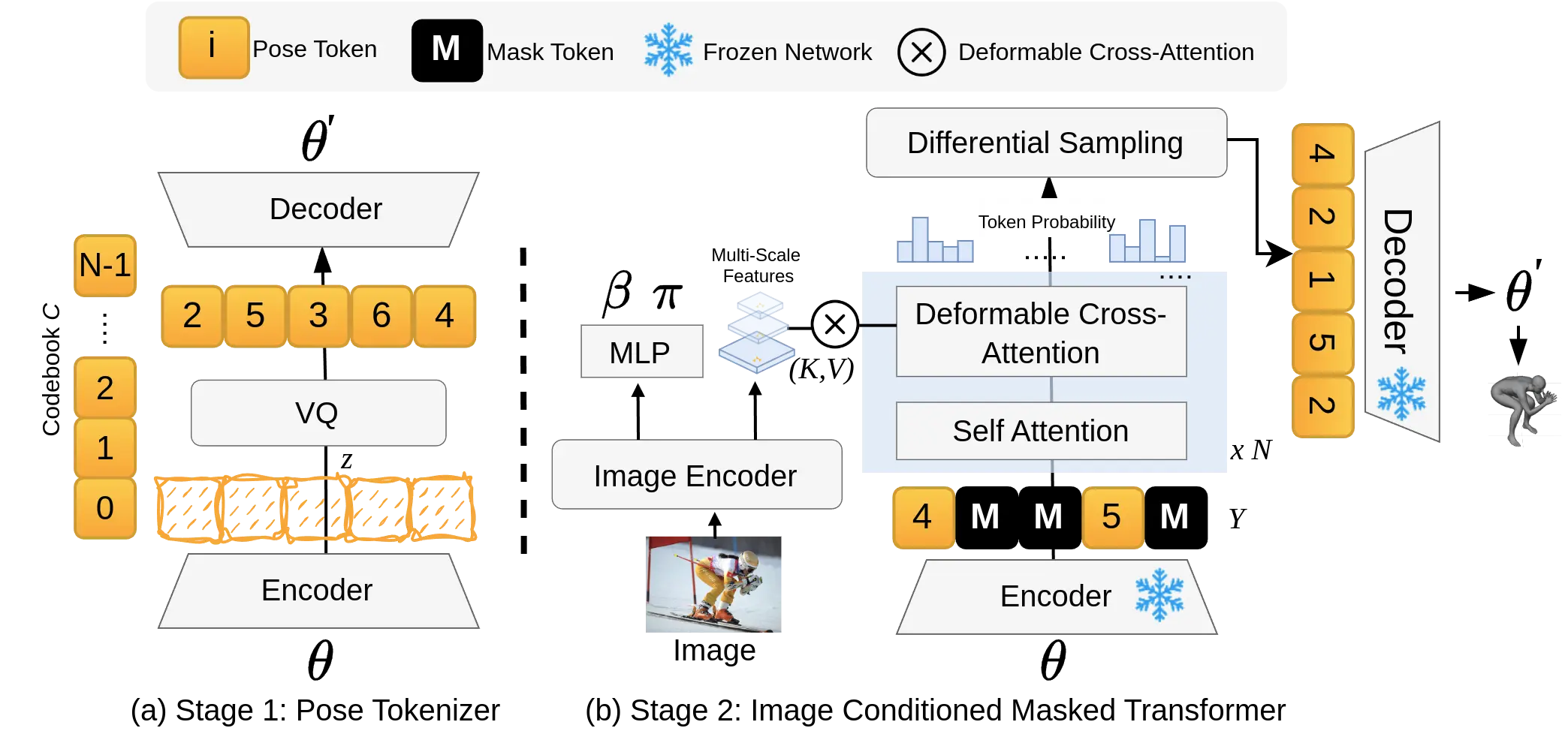
Uses a Pose Tokenizer and Image-Conditioned Masked Transformer to convert poses into simplified codes for processing.
Examples of GenHMR in Action
1. High-Action Scenes
One of the standout examples involves a high-action scene where characters are running and performing acrobatic moves across rooftops. Despite the fast-paced and dynamic movements, GenHMR accurately predicts the poses of these characters. The AI manages to keep up with the rapid changes in their positions, showcasing its ability to handle complex scenarios.
2. Chaotic War Scenes
Another example features a chaotic war scene with multiple people running around, explosions occurring, and general mayhem. Even in such a disorderly environment, GenHMR successfully detects the poses of most characters with high accuracy. This demonstrates its robustness in handling crowded and unpredictable situations.

3. Race Footage
In this example, GenHMR is applied to footage of a race. Here, the AI detects the poses of all the runners with remarkable precision. This further highlights its capability to analyze and interpret human movements in various contexts.
4. Performance Analysis
From these examples, it's clear that GenHMR excels at detecting the poses and 3D models of multiple humans in a video, even in challenging scenarios. The system demonstrates:
- Accurate pose detection in fast-paced scenes
- Robust performance with multiple subjects
- Reliable tracking in crowded environments
- Precise 3D model generation from complex movements
5. Additional Demo
Here's another demonstration of GenHMR's capabilities in action:

Pros and Cons
Pros
- Accurate pose detection in fast-paced scenes
- Handles multiple people simultaneously
- Works well in crowded environments
- No need for marker suits or special equipment
- Two-stage refinement for better accuracy
Cons
- Misaligned poses in complex movements
- Struggles with wide-angle shots
- Code not publicly available yet
- May have perspective distortion issues
- Accuracy varies with camera angles
How GenHMR Works
Step 1: Training Phase
The system first trains using two key components:
- A Pose Tokenizer that converts complex 3D human poses into simplified token sequences
- An Image-Conditioned Masked Transformer that learns to predict 3D poses from these tokens and input images
Step 2: Uncertainty-Guided Sampling
In the first inference stage, GenHMR:
- Generates multiple possible 3D poses for all people in the video
- Evaluates each pose's probability based on the input image
- Selects the most likely pose configuration as the initial estimate
Step 3: 2D Pose-Guided Refinement
The second stage refines the initial poses through:
- Iterative adjustment of the 3D model to better match the 2D image
- Progressive error correction over multiple refinement steps
- Fine-tuning of pose details for improved accuracy
Step 4: Refinement Process
The system performs up to 10 refinement steps to:
- Correct initial pose estimation errors
- Improve alignment with the input image
- Enhance overall pose accuracy and natural appearance
Step 5: Final Output
GenHMR produces highly accurate 3D human mesh reconstructions that:
- Handle challenging poses effectively
- Work well even in complex scenarios
- Outperform previous methods like HMR2.0 and TokenHMR